1. Introduction
Databricks is a unified data analytics platform that provides a fully managed cloud-based environment for data engineering, data science, and machine learning workloads.
This article outlines the main steps to follow for setting up a Databricks architecture on AWS.
2. Steps for Setting Up a Databricks Architecture
Here are the main steps to follow for setting up a Databricks architecture on AWS as part of the migration to Databricks:
Evaluation of the Existing Environment: Start by analyzing the current infrastructure, data sources, transformations, workloads, and dependencies. This will help you understand the specific requirements and plan the migration.
Design of the Databricks Architecture: Define the Databricks architecture, including the number of clusters, node configuration (instance type, number of cores, memory), storage (S3, ADLS, etc.), network connectivity, and security (IAM, virtual networks, etc.).
Configuration of the AWS Environment: Set up the necessary AWS environment, such as accounts, IAM roles, virtual networks, security groups, etc.
Deployment of Databricks: Deploy the Databricks environment on AWS, creating the workspace, clusters, libraries, etc.
Data Migration: Migrate the source data from its current location to AWS storage (S3, ADLS, etc.) using tools like AWS DataSync, Distcp, or custom scripts.
Migration of Transformations: Convert the existing transformations into Databricks notebooks or Databricks pipeline tasks. You can use automated migration tools or perform a manual conversion.
Testing and Validation: Test the migrated transformations and validate the results to ensure that the data and business logic are correctly transferred.
Training and Documentation: Train the team on the use of Databricks and document the processes, pipelines, and best practices.
Production Deployment: Once testing is successful, deploy the Databricks clusters, pipelines, and workloads into production.
Monitoring and Maintenance: Establish monitoring processes, log management, updates, and maintenance of the Databricks environment.
During the first days of the mission, you should focus on the following points:
Understand the client’s business and technical requirements
Evaluate the existing environment
Design a preliminary Databricks architecture
Set up AWS accounts and required services
Deploy a basic Databricks environment for testing
3. Setup Databricks on AWS
3.1. Sign up to Databricks (AWS cloud)
Head over to databricks.com/try-databricks and create a new databricks account. Make sure to enter the workspace name and AWS region
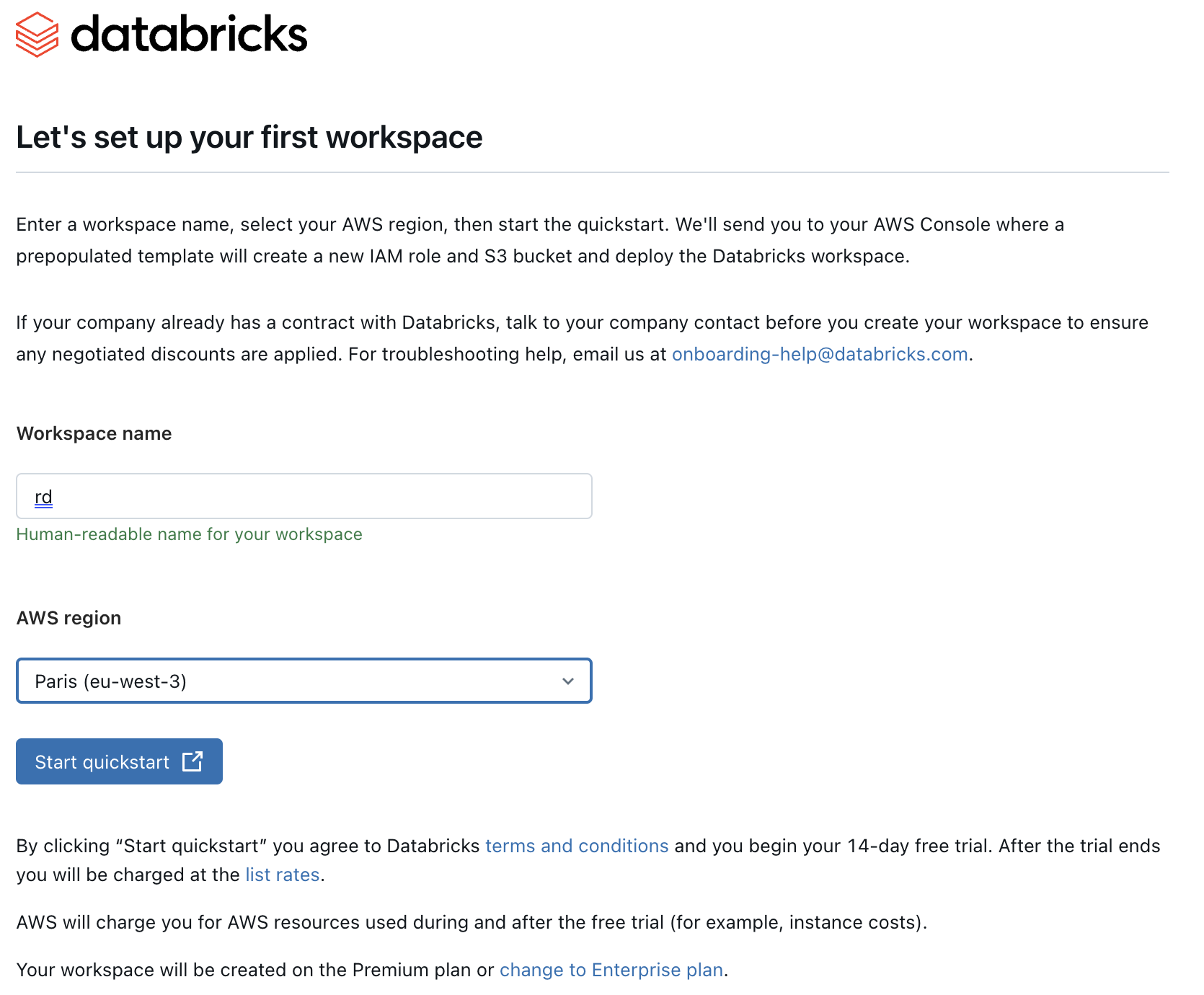
After clicking on the URL sent by email, you will be redirected to this databricks page :
Email adresse of the Databricks Onboarding Desk : onboarding-help@databricks.com
3.2. Create a Databricks workspace
Click on Create a workspace button on Databricks and chose Quickstart (Recommended) option
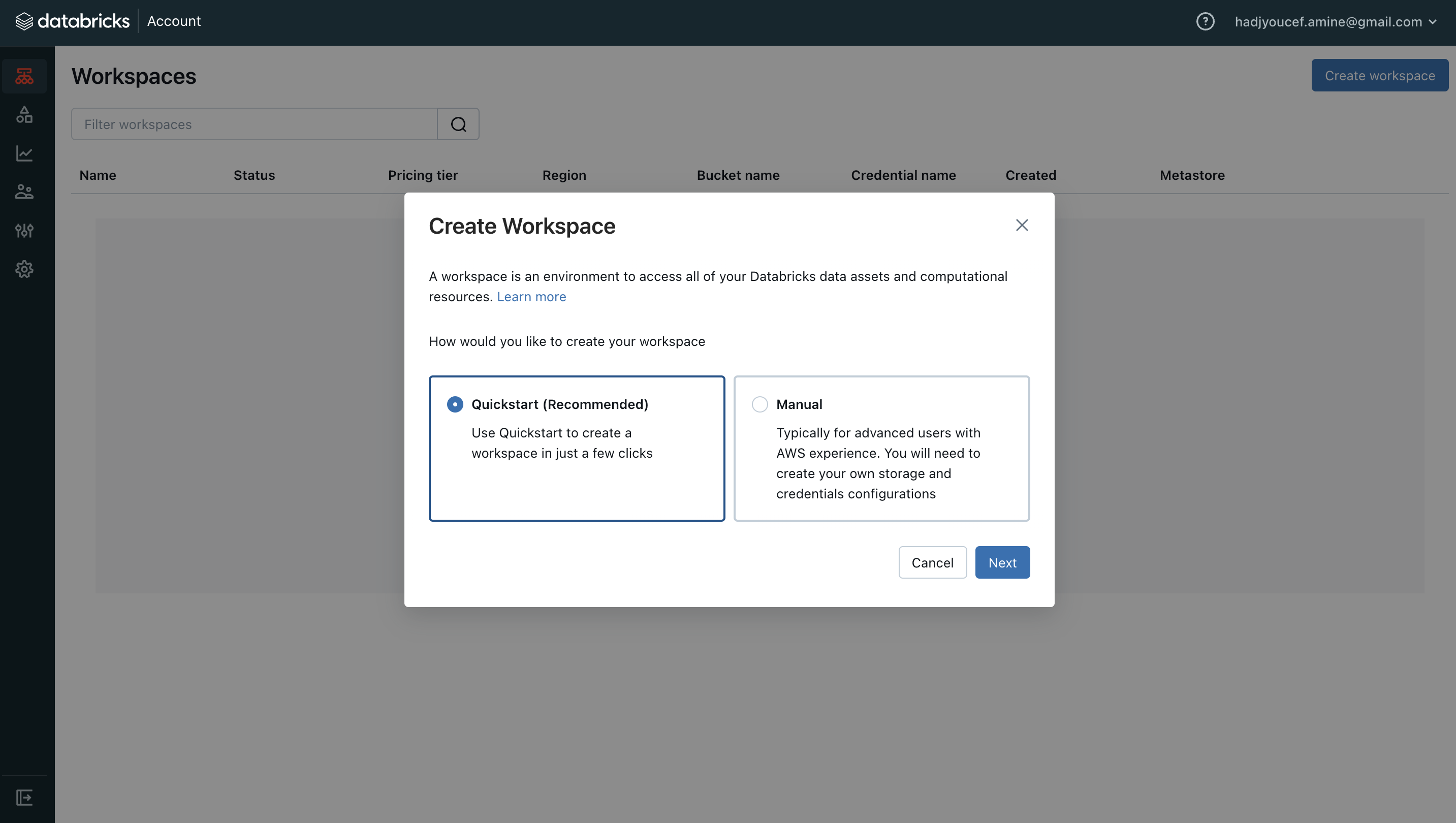
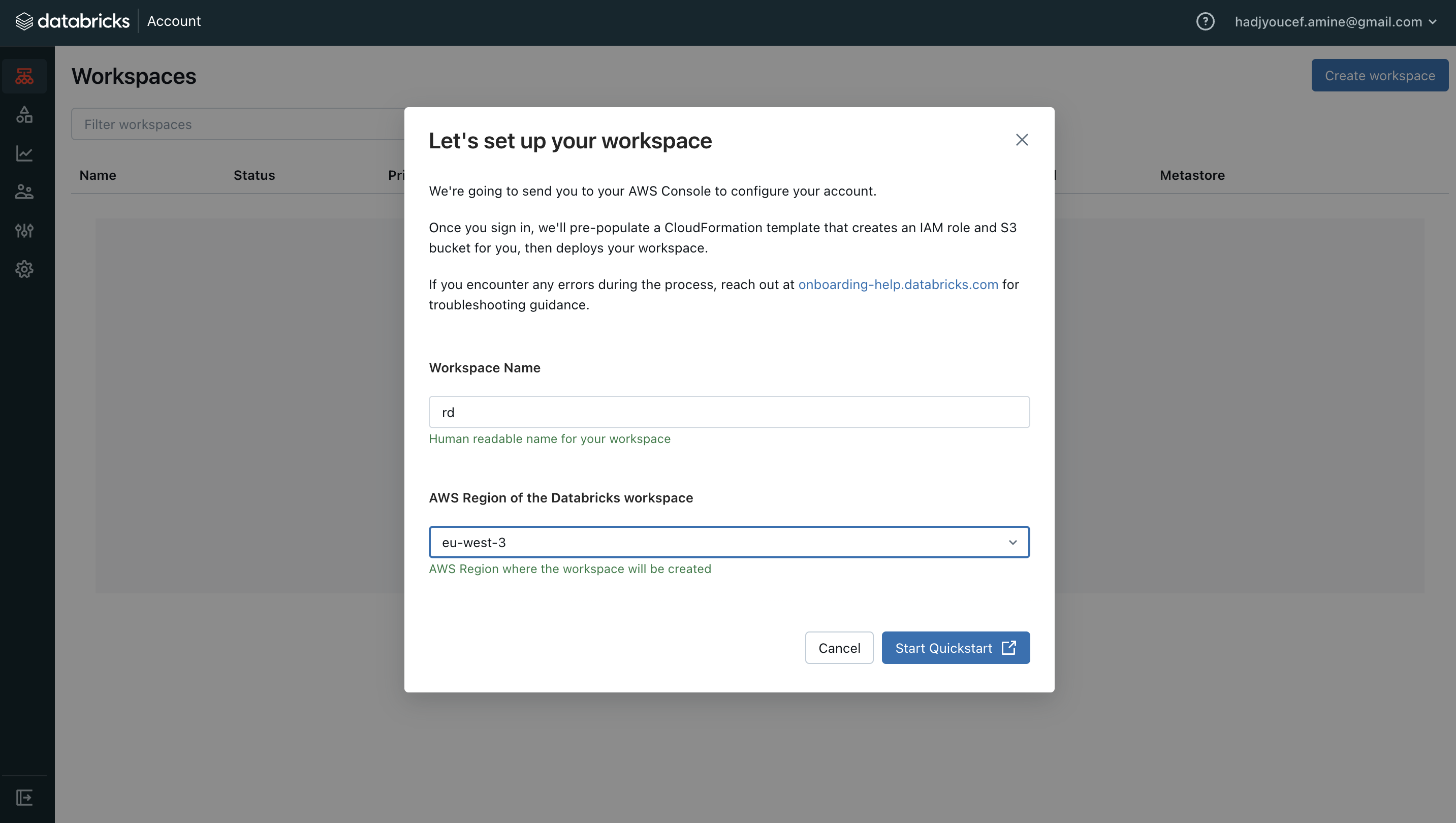
By clicking on Start Quickstart, you will be directed to AWS.
3.3. Setup a stack on AWS
Next, we have to create a stack on AWS using a template provided by Databricks databricks-trial.template.yaml
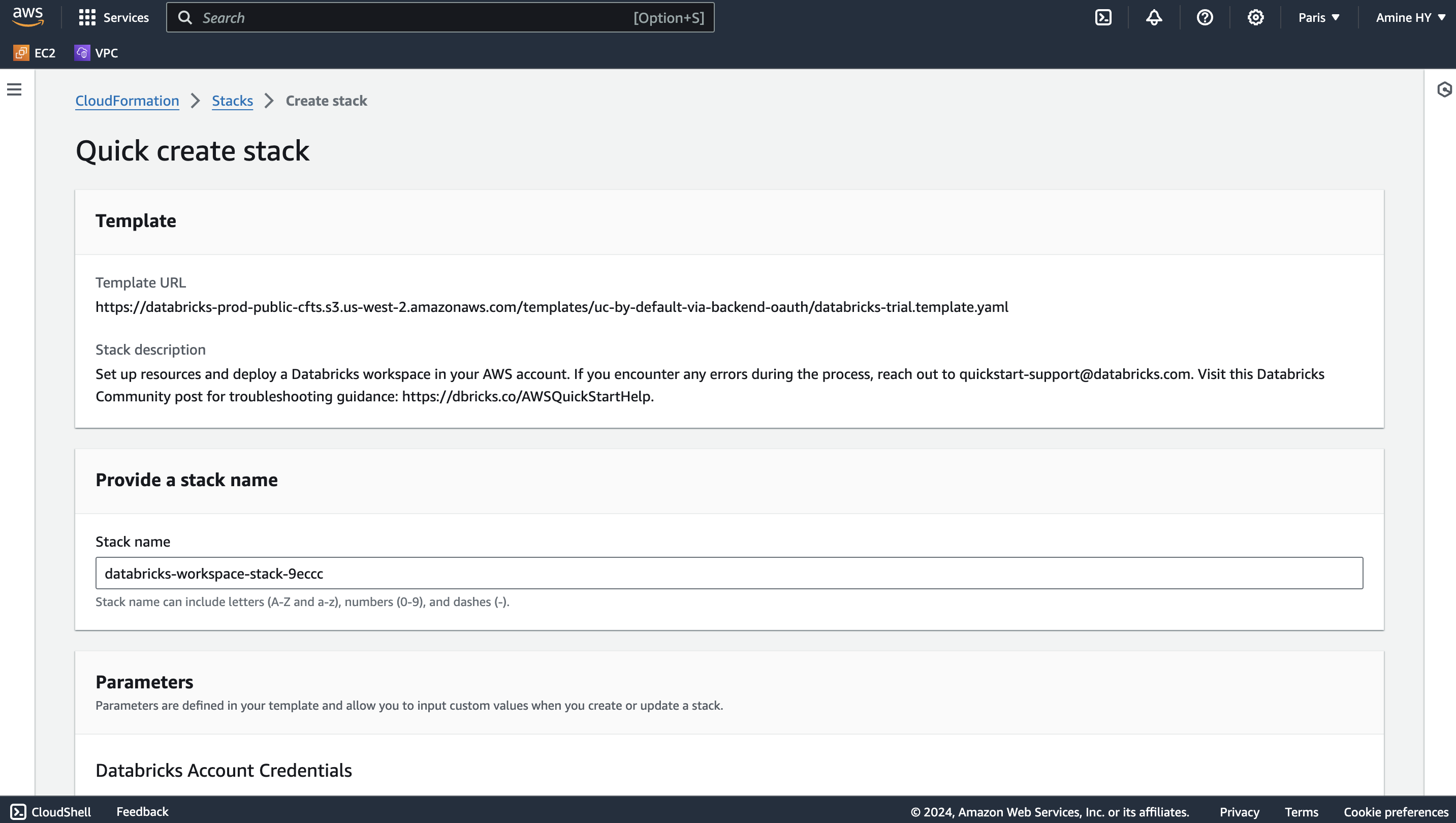
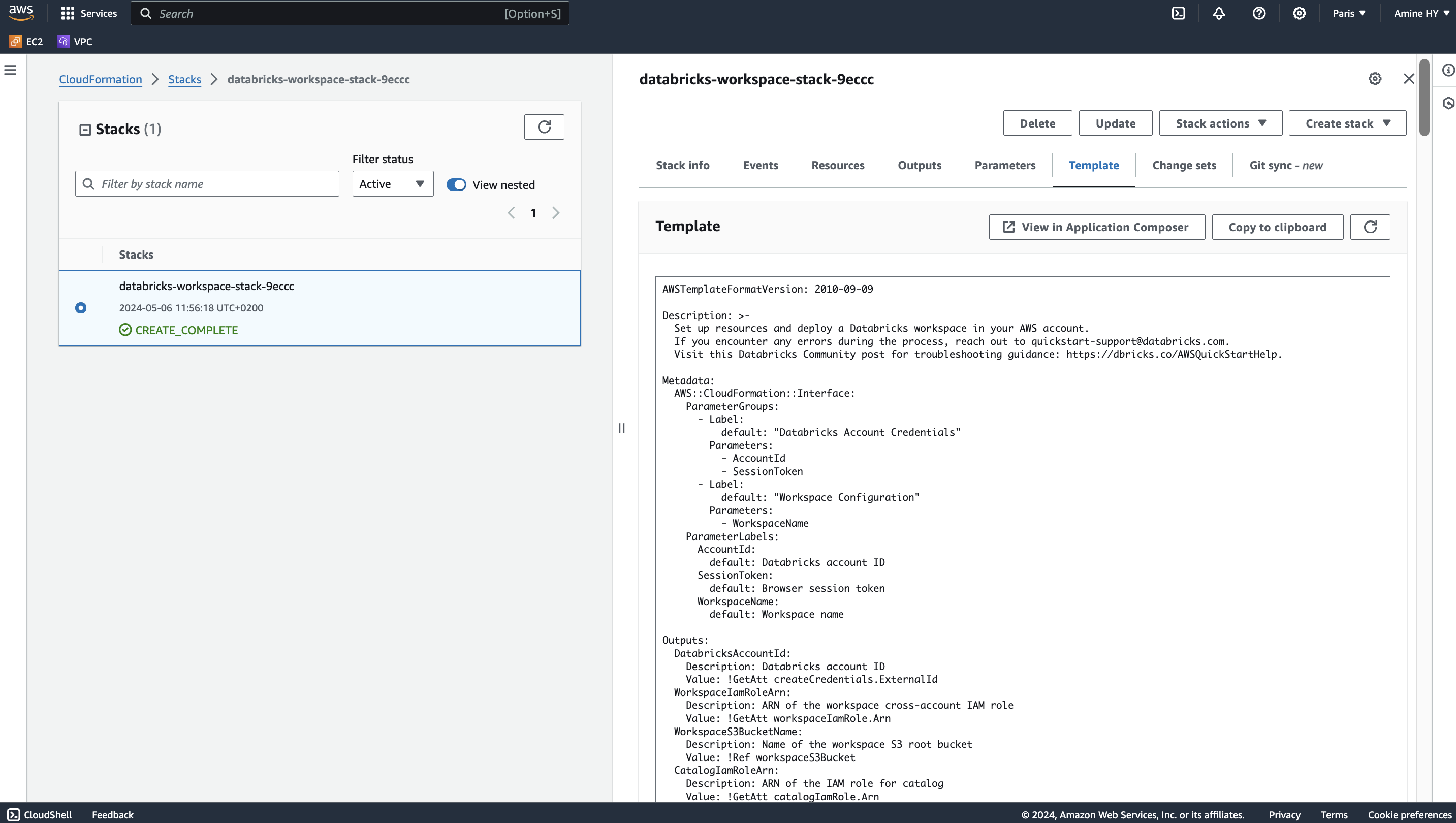
3.4. Understand the stack template
The template sets up the following (IAM Role, S3 Bucket, Lambda Function) resources for deploying a Databricks workspace on AWS:
IAM Role (
workspaceIamRole): This role is assumed by Databricks to manage resources within your AWS account, such as creating VPCs, subnets, security groups, and EC2 instances.S3 Bucket (
workspaceS3Bucket): This bucket is used as the root storage location for the Databricks workspace. It stores notebook files, data, and other artifacts.IAM Role (
catalogIamRole): This role is used by Databricks to access the S3 bucket for the Unity Catalog metastore.Lambda Function (
createCredentials): This function interacts with the Databricks API to create credentials for the workspace, associating it with theworkspaceIamRole.Lambda Function (
createStorageConfiguration): This function interacts with the Databricks API to create a storage configuration for the workspace, associating it with theworkspaceS3Bucketand thecatalogIamRole.Lambda Function (
createWorkspace): This function interacts with the Databricks API to create the Databricks workspace itself, using the credentials and storage configuration created by the previous Lambda functions.Lambda Function (
databricksApiFunction): This is a helper function that the other Lambda functions use to interact with the Databricks API.IAM Role (
functionRole): This role is assumed by the Lambda functions to perform their respective tasks.S3 Bucket (
LambdaZipsBucket): This bucket is used to store the Lambda function code (lambda.zip) during the deployment process.
The relationships between these resources can be summarized as follows:
The
workspaceIamRoleandcatalogIamRoleare associated with the Databricks workspace during its creation.The
workspaceS3Bucketis used as the root storage location for the Databricks workspace.The
createCredentials,createStorageConfiguration, andcreateWorkspaceLambda functions interact with the Databricks API to set up the required components (credentials, storage configuration, and workspace) for the Databricks deployment.The
databricksApiFunctionLambda function is used by the other Lambda functions to interact with the Databricks API.The
functionRoleis assumed by the Lambda functions to perform their respective tasks.The
LambdaZipsBucketis used to store the Lambda function code during the deployment process.
3.5. Create a stack on AWS
Here is the list of parameters to enter in the stack creation page :
Stack name, e.g. databricks-workspace-stack-9eccc
Account ID (AccountId), e.g. 6b922be2-a681-4ca1-91f0-4069055b61e2
Session Token (SessionToken): auto generated from Databricks
Workspace name (WorkspaceName), e.g. rd
IAM role - optional
Click on Create Stack button, multiple events will be displayed regarding our stack creation
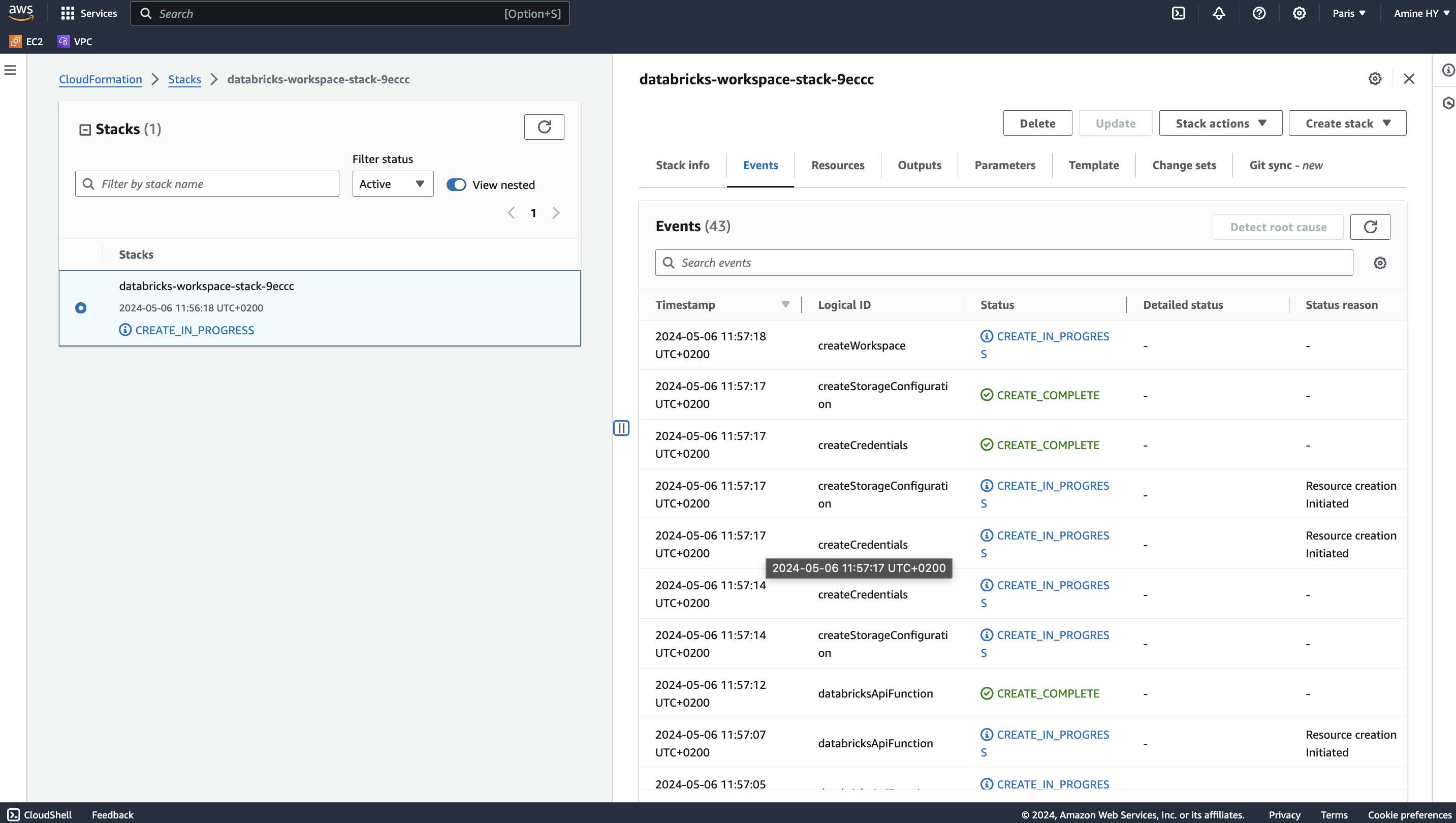
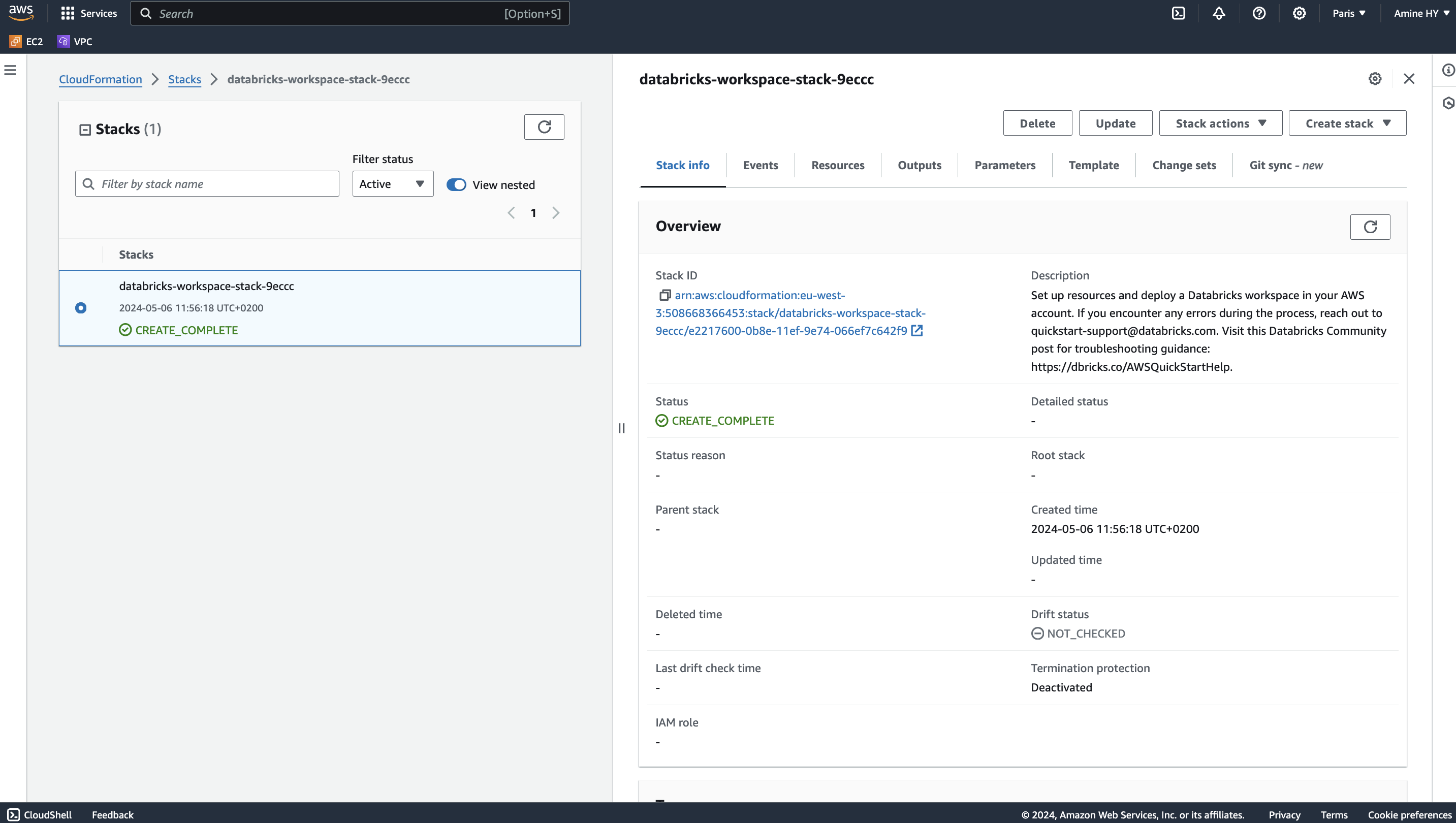
3.6. Using Databricks Workspace
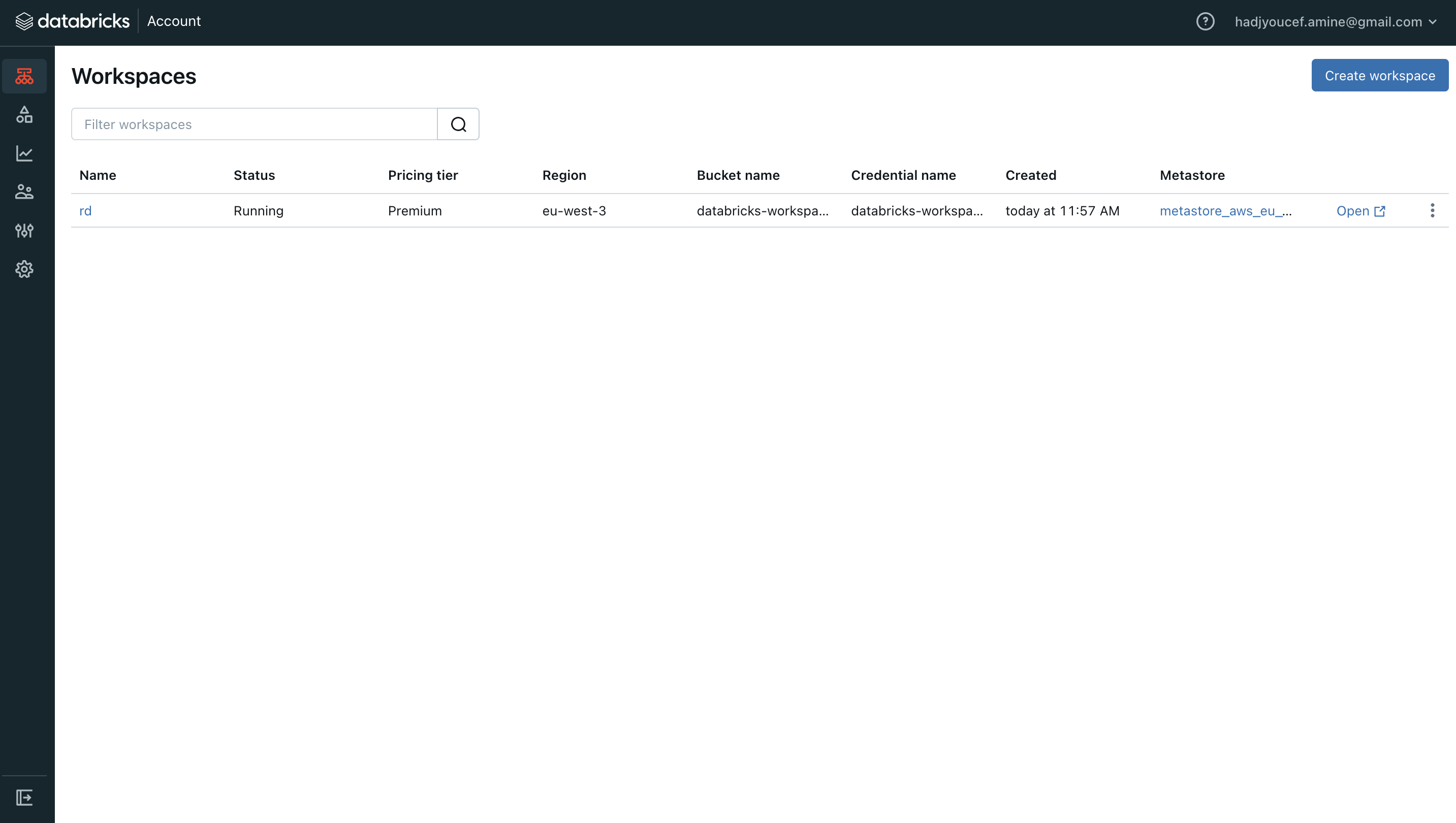
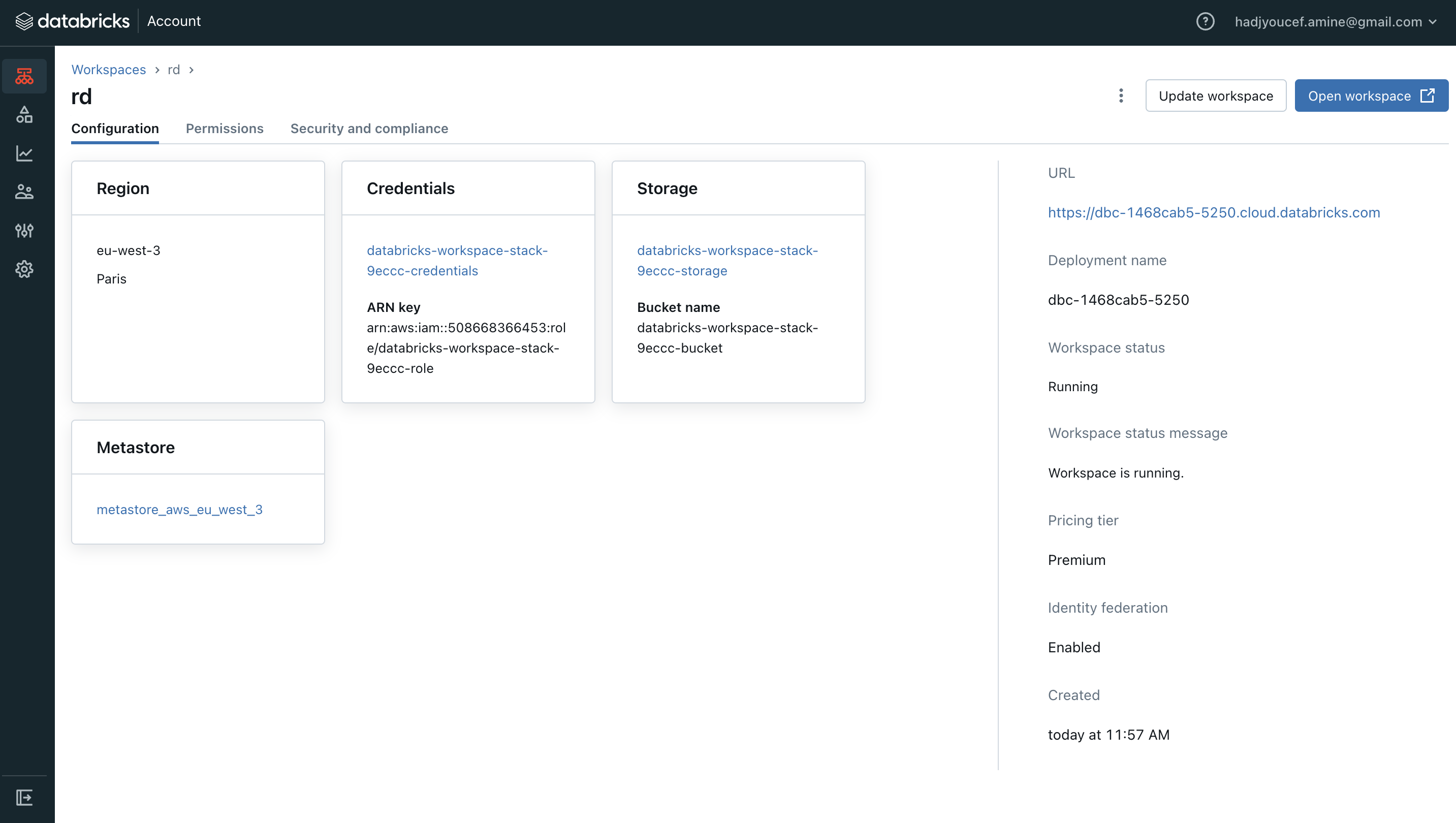
3.7. AWS Stack for different Databricks Workspace
The template for creating AWS Stack could be used to replicate a stack for as many workspace as required.
Possible workspace names:
Prod for Production
Pre Prod (pp) for Production
Dev or Rd for Development
Test or QA for Quality Assurance
Staging for Staging
or by adding a reference for country, team…
Prod-EU-DataTeam
Dev-US-ProjectX
4. Platform Administration Cheat-sheet
| Best Practice | Impact | Docs |
|---|---|---|
Enable Unity Catalog | Data governance: Unity Catalog provides centralized access control, auditing, lineage, and data discovery capabilities across Databricks workspaces. | |
Use cluster policies | Cost: Control costs with auto-termination (for all-purpose clusters), max cluster sizes, and instance type restrictions.
Observability: Set | |
Use Service Principals to connect to third-party software | Security: A service principal is a Databricks identity type that allows third-party services to authenticate directly to Databricks, not through an individual user’s credentials. If something happens to an individual user’s credentials, the third-party service won’t be interrupted. | |
Set up SSO | Security: Instead of having users type their email and password to log into a workspace, set up Databricks SSO so users can authenticate via your identity provider. | |
Set up SCIM integration | Security: Instead of adding users to Databricks manually, integrate with your identity provider to automate user provisioning and deprovisioning. When a user is removed from the identity provider, they are automatically removed from Databricks too. | |
Manage access control with account-level groups | Data governance: Create account-level groups so you can bulk control access to workspaces, resources, and data. This saves you from having to grant all users access to everything or grant individual users specific permissions. You can also sync groups from your identity provider to Databricks groups. | |
Set up IP access for IP whitelisting | Security: IP access lists prevent users from accessing Databricks resources in unsecured networks. Accessing a cloud service from an unsecured network can pose security risks to an enterprise, especially when the user may have authorized access to sensitive or personal data Make sure to set up IP access lists for your account console and workspaces. | |
Configure a customer-managed VPC with regional endpoints | Security: You can use a customer-managed VPC to exercise more control over your network configurations to comply with specific cloud security and governance standards your organization might require. Cost: Regional VPC endpoints to AWS services have a more direct connections and reduced cost compared to AWS global endpoints. | |
Use Databricks Secrets or a cloud provider secrets manager | Security: Using Databricks secrets allows you to securely store credentials for external data sources. Instead of entering credentials directly into a notebook, you can simply reference a secret to authenticate to a data source. | |
Set expiration dates on personal access tokens (PATs) | Security: Workspace admins can manage PATs for users, groups, and service principals. Setting expiration dates for PATs reduces the risk of lost tokens or long-lasting tokens that could lead to data exfiltration from the workspace. | |
Use system tables to monitor account usage | Observability: System tables are a Databricks-hosted analytical store of your account’s operational data, including audit logs, data lineage, and billable usage. You can use system tables for observability across your account. |